2.3 吃透 Pod 中的第三类容器 – init 容器¶
从上一篇文章,我们已经知道了一个 Pod 至少会有两种容器, pause 容器和 应用容器。
注意我的表述是 至少,这其实已经在暗示 Pod 里还存在其他类型的容器,这就是我们本篇文章的主角 – init 容器。

2-3-1 Pod Init Container¶
init 容器和 pause 容器有相同点,也有不同点
相同点在于:它们都有固定用途,是专用的特殊容器
不同点在于: init容器是用户级的容器,它是由用户来定义的,而 pause 容器是系统级容器,它不是由用户定义的。
init 容器会在应用(业务)容器启动之前运行,用来包含一些应用镜像中不存在的实用工具或安装脚本。
1. init 容器的运行机制¶
init 容器,从名字上来看,也能看出是的用途就是运行一些初始化任务,来保证应用容器运行环境。
这就决定了:
init 容器必须先于 应用容器启动
仅当 init 容器完成后,才能运行应用容器
一个 Pod 允许有多个 init 容器,做不同的初始化任务
当一个 Pod 有多个 init 容器时,这些 init 容器是顺序运行的,一个 init 容器完成之后,才会运行一个 init 容器。
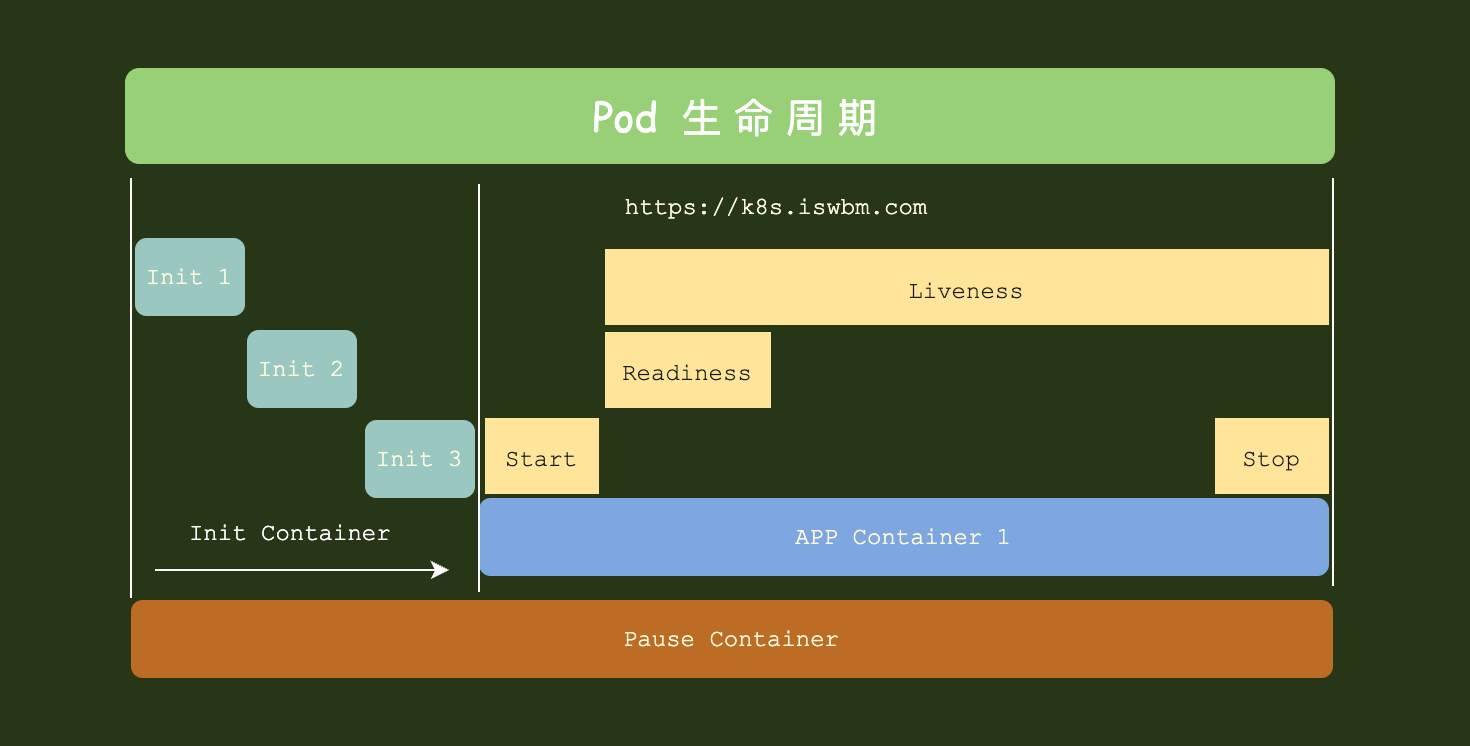
2-3-2 Pod Lifecycle¶
因此如果你在 kubectl get po 时加一个 -w 参数,就能看到 Pod
状态的变化过程
在正常情况下(默认 Pod 的 restartPolicy 为 Always),只要有一个 init
容器运行失败,整个 Pod 便会不停地重启,直到 init 容器全部运行完成为止。
而只要一个 Pod 重启,不管init 容器之前有没有执行过,所有的 init 容器都要重新执行一遍。
2. init 容器与应用容器¶
init 容器与应用容器,除个别配置之外,基本一致,不用付出太多额外的学习成本。
不一样的地方有哪些呢?
第一点不同
定义位置不同。
应用容器定义在 Pod.Spec.Containers,是必填字段,而 init 是定义在 Pod.Spec.initContainers 中,是可选字段。
第二点不同
部分配置不同。
init 容器没有 Lifecycle actions, Readiness probes, Liveness probes 和 Startup probes,而这些应用容器都有。
另外,虽然 init 容器与应用容器是两个类别的容器,但由于属于同一个 Pod ,因此容器的名字,是不能重复的。
3. init 容器的资源问题¶
当一个 Pod 只有应用容器时,那么在 kube-scheduler 调度该 Pod 时,会将所有的应用容器的 requests/limits 资源进行相加,得到一个requests/limits 的总量。
然后拿这个总量,去跟 node 上的可用资源进行比较,若 node 上的资源充足,则允许调度过去,反之则不允许。
而现在有了 init 容器后,情况会稍微复杂一点。
我以 requests.cpu 为例,来实践一下 kube-scheduler 到底是如何请求的资源问题的。
而 limits 以及其他资源类型(如 memory)都是一样的道理。
下面是一个包含一个应用容器和两个 init 容器的 Pod 的配置文件。
# init-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: test-init-pod
labels:
app: init
spec:
containers:
- name: myapp
image: busybox
resources:
requests:
cpu: 100m
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-01
image: busybox
command: ['sh', '-c', 'sleep 10']
resources:
requests:
cpu: 20m
- name: init-02
image: busybox
command: ['sh', '-c', 'sleep 10']
resources:
requests:
cpu: 30m
我们只是想实践看看这些 resources 的资源是如何计算的,因此容器里的 command 内容可以不用关注,怎么简单怎么来,全都是 sleep 。
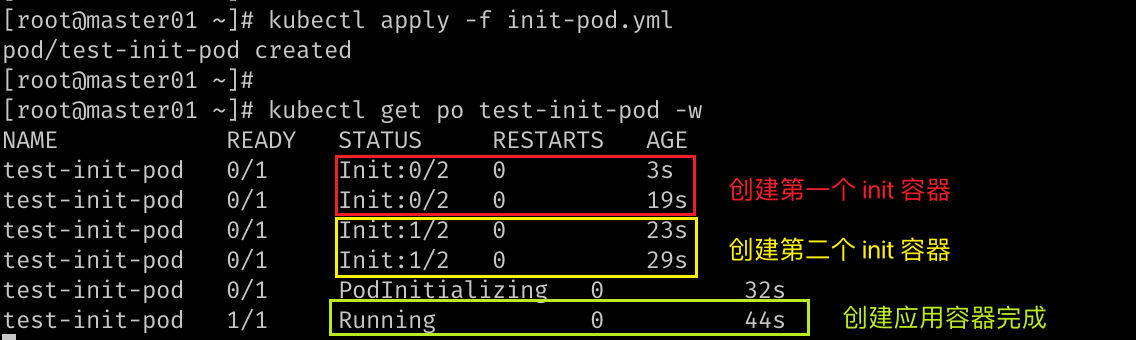
使用 kubectl apply -f init-pod.yml 创建该 pod 之后,再使用
kubectl get po -o wide 查看一下创建到哪一台 node 上。
假设创建到 worker01 上,使用 kubectl describe node worker01
就可以看到该 node 上的所有 pod 的详情,包括资源占用情况。
可以看到 requests.cpu 总量计算为 100m,这刚好是应用容器的 requests.cpu
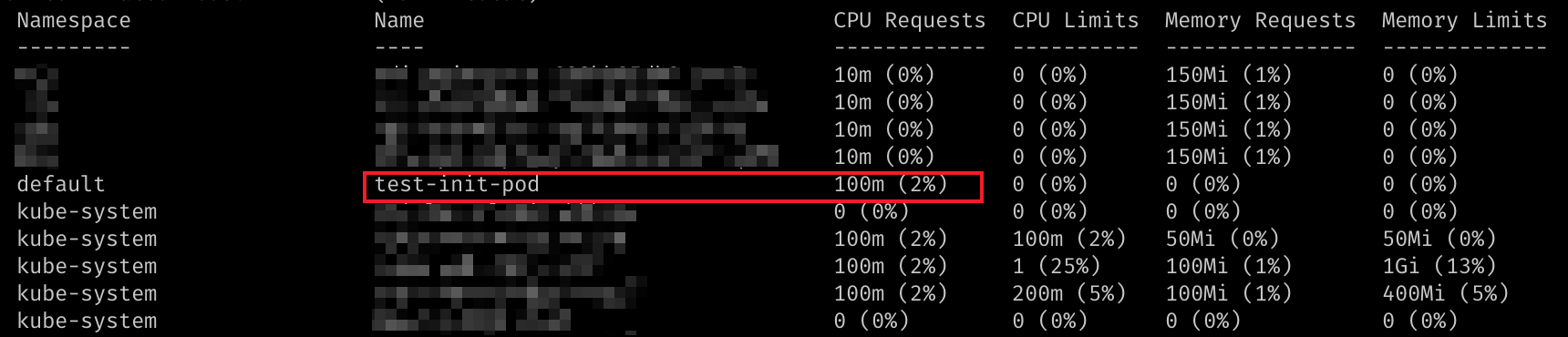
在此你可能会认为,调度参考的资源总量只考虑了应用容器。
实际上,并不是这样,可以尝试把上面的配置文件里,应用容器 cpu 数据下调为 10m,小于其他任意容器的值。
# init-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: test-init-pod
labels:
app: init
spec:
containers:
- name: myapp
image: busybox
resources:
requests:
cpu: 10m
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-01
image: busybox
command: ['sh', '-c', 'sleep 10']
resources:
requests:
cpu: 20m
- name: init-02
image: busybox
command: ['sh', '-c', 'sleep 10']
resources:
requests:
cpu: 30m
再次使用 describe 查看 node,发现该 pod 的 requests.cpu 只剩下 30m,这不刚好是 init-02 请求的资源值吗?

善于总结规律的你,应该已经想到了 kube-scheduler 的套路,我这里再补充总结一下:
1. 当只有应用容器时
由于应用容器是同时运行的,因此为了保证应用容器的正常运行,请求的资源总量应当是所有应用容器的各自请求的资源之和。
2. 当有 init 容器时
由于 init 容器会先于应用容器运行,只有当 init 运行成功并且退出后,应用容器才会运行,因此为了保证所有的容器(不仅包括应用容器,还包括 init 容器)的运行,pod 的资源总量的计算公式如下
max(应用容器请求资源之和,max(所有的 init 容器请求资源))
4. init 容器的应用场景¶
上面我们以简单的例子来理解 init 容器的运行机器和资源计算,每个容器都运行简单的 sleep 命令,并没有代入实际的业务场景,也许会让你以为 init 容器和普通的应用容器没什么区别。
实际上并不是那样子的,那 init 容器到底有什么用呢?它的应用场景又有哪些呢?
举一个最简单的例子,假设我们有一个 Web 服务,该服务又依赖于另外一个数据库服务。
但是在在启动这个 Web 服务的时候,我们并不能保证依赖的这个数据库服务就已经启动起来了,所以可能会出现一段时间内 Web 服务连接数据库异常。
要解决这个问题的话我们就可以在 Web 服务的 Pod
中使用一个InitContainer,在这个初始化容器中去检查数据库是否已经准备好了,准备好了过后初始化容器就结束退出,然后我们的主容器Web
服务被启动起来,这个时候去连接数据库就不会有问题了。
但其实不用 initContainer 的话,这部分依赖的检查实际也可以移入应用容器的程序中,确实是如此。
那为什么 K8S 还要提供一个 initContainer 的入口呢?
这就好像,你使用计算器计算 5 个 88 相加的结果是使用
88+88+88+88+88,还是使用 88*5 是一个道理。
计算器提供这个功能,至于你用不用?怎么用?都取决于用户自己。
但从 K8S 这个平台来考虑,提供了这个接口,就可以把一个大而重的程序分割成多个小的细分模块,不仅有利于编码和维护,还能让应用程序的之间的依赖关系更加清晰。