1. 排查 K8S Pod 被 OOM 的思路及建议¶
K8S + 容器的云原生生态,改变了服务的交付方式,自愈能力和自动扩缩等功能简直不要太好用。
有好的地方咱要夸,不好的地方咱也要说,真正的业务是部署于容器内部,而容器之外,又有一逻辑层 Pod 。
对于容器和 K8S 不怎么熟悉的人,一旦程序发生了问题,排查问题就是个头疼的问题。
这两天一直在排查一个 Pod OOM 的问题,花了不少的时间,感觉有必要写下来,帮助自己梳理的同时,也能给其他人一些思路。
1. 问题描述¶
事情的主角是 kubevirt 的一个开源项目叫 cdi,它的用途是在虚拟机启动之前将虚拟机的镜像导入到系统盘中。
在使用过程中,我们发现 cdi 在导入数据时会占用大量的内存空间。
而 cdi-controller 在创建 cdi-importer 的 pod 时,默认限定其最高只能使用 600M 的内存,到最后呢,pod 就发生了 OOMKilled。
[root@master01 ~]# kubectl get po
NAME READY STATUS RESTARTS AGE
importer-wbm-vda 0/1 OOMKilled 1 76s
经过测试,cdi-importer 的 limits.memory 要设置 6 个 G 才比较保险。
我们一致都对 cdi-importer 要占用 6G 内存表示费解,想找下原因,看看有没有优化的空间。
2. 思路一:内存泄露¶
我第一时间想到的是,有没有可能是代码问题导致发生了内存泄露?
当即使用 ps aux 和 top -p [pid] 工具去查看进程的
rss,发现程序本身的内存占用并不高,最多才 50M。
和 limits.memory=600M 相比,差得有点大,按道理是不可能出现 OOM 的,怎么回事呢?难道 top 和 ps 的数据不准?
正常检查 Go 程序的内在泄露,会使用 pprof 工具,不如我再用 pprof 去分析一下内存吧,做个双向验证吧
在程序入口处加一如下代码后
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:35526", nil))
}()
// more code...
}
再次使用 bazel 进行编译,制作镜像,创建 pod
然后通过 kubectl top pod xxx
观察内存的变化,在将到达最大值的时候,调用如下命令开启一个 pprof
的交互式界面
go tool pprof http://ip:port/debug/pprof/heap
输入 top 就可以看到占用内存前 10 的函数调用,可以看到程序占用的总内存也才8M 而已,占用最高的函数也才 4M
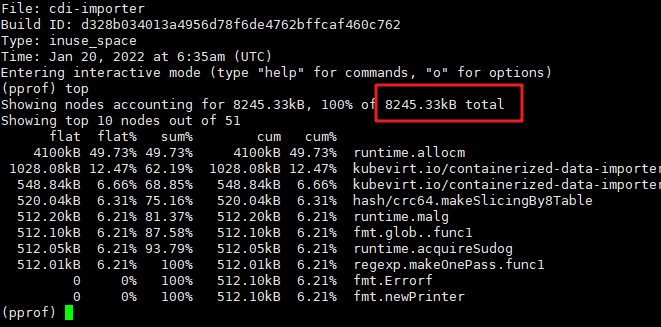
到这边,已经基本可以确定程序本身没有发生所猜想的内存泄漏。
3. 思路二:查看 OOM 日志¶
发生了 oom ,不如看看 oom 的日志,看看能不能发现点什么?
通过 dmesg 打印出 oom 的相关日志
[580237.375615] memory: usage 585936kB, limit 585936kB, failcnt 75129
[580237.375616] memory+swap: usage 585936kB, limit 9007199254740988kB, failcnt 0
[580237.375618] kmem: usage 24148kB, limit 9007199254740988kB, failcnt 0
[580237.375618] Memory cgroup stats for /kubepods/burstable/pod6b212546-f5dd-4fdf-bcc7-72a686638102:
[580237.375639] [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
[580237.375949] [17998] 0 17998 242 1 28672 0 -998 pause
[580237.375955] [18524] 0 18524 675338 5758 499712 0 999 cdi-importer
[580237.375963] [ 3422] 0 3422 191966 4380 327680 0 999 qemu-img
[580237.375966] oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=ea887b1c9c5c8e734ac798fedd2bf5d39c0b7ce5ad961027dfc1ca138a23a2e8,mems_allowed=0-1,oom_memcg=/kubepods/burstable/pod6b212546-f5dd-4fdf-bcc7-72a686638102,task_memcg=/kubepods/burstable/pod6b212546-f5dd-4fdf-bcc7-72a686638102/ea887b1c9c5c8e734ac798fedd2bf5d39c0b7ce5ad961027dfc1ca138a23a2e8,task=cdi-importer,pid=18524,uid=0
[580237.376066] Memory cgroup out of memory: Killed process 18524 (cdi-importer) total-vm:2701352kB, anon-rss:23032kB, file-rss:0kB, shmem-rss:0kB, UID:0
[580237.466313] oom_reaper: reaped process 18524 (cdi-importer), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
日志的最开始处,打印了内存的限制为 585936 kb,而当前已使用 585936kb,这么看确实是不够了。
但到底哪里不够用了呢?
从后面的日志 cdi-importer 的 rss 才 23032kB,23 M 而已,应该还剩 500 多 M 啊,怎么就说我不够了?
这下真的麻了,一个问号还没有解决,脑子里又蹦出来新的问号。
4. 思路三:缓存做崇¶
通过不断的 Google 搜索,我查到了 kubectl top 得到的内存使用数据原来是这么计算的
memory.usage_in_bytes-total_inactive_file
从这个公式可以看出, kubectl top 得到的内存使用数据原来是包含 cache 的。
到这里,我相信很多人会认为 k8s 这样的计算是不准确的,rss 才是进程真正使用的内存吧。
起初,我也是这么觉得的,直到我翻看了 k8s 关于这块的 issue 已经存在很多年了,一直到至今还没有解决,出于对 k8s 开发团队的信任,我选择相信这种计算方式是“正确的”,全球顶尖的开发团队会放任一个 bug 存在如此之久?
可就算是正确的又怎样呢?问题仍然摆在这里,并没有一丝一毫的进展。
就在我一筹莫展的时候,前面的 cache 让我有一点灵感。
在 OOM 后,我特地去查看了该容器的 cgroup 文件,发现在 memory.meminfo 里的 free 已经小于 1M 了,而相反的 cached 的值却几乎等于容器的最高内存限制。
突然之间,我感觉到曙光就在眼前,有可能还真的是 cache 占用了内存才导致的 OOM
回想一下,正常的 cache 可以提高磁盘数据的读写数据,在读的时候,会拷贝一份文件数据放到内存中,这部分是可回收的,一旦程序内存不足了,会回收部分 cache 的空间,保证程序的正常运行。
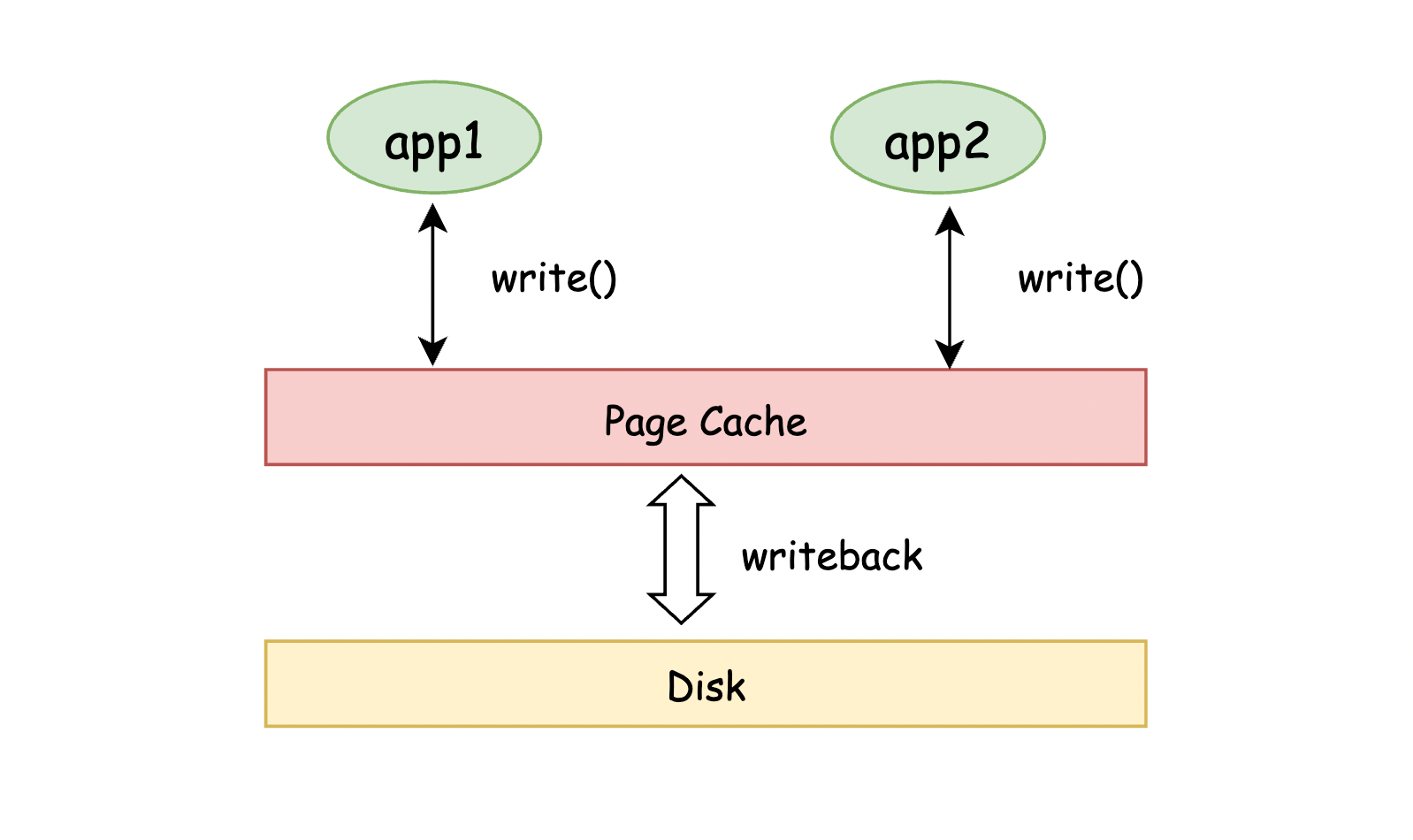
可见读文件的缓存,不会影响内存的申请,更别说 OOM,但在写的时候,情况就不一样了
在写的时候,由于进程处理数据的速度,可能会远大于数据落盘的速度,所以为提高格式转化和数据导入的速度,一般会先将转化好的数据存入缓存中,存入缓存后,进程可以立马 return 回去继续下一堆数据的处理,不用傻傻地等待数据全写入磁盘。
而存在于缓存之中的数据,则由操作系统同步写入磁盘,这样一来,数据落盘就变成了一个异步的过程,大大提高了写入的速度。
大腿一拍,这不就有可能会出问题吗?
如果 qemu-img 处理数据的速度远大于 cache 存入磁盘的速度,就会出现内存不足啦。
问题好像发现了,可该如何验证呢?
去查看了一下 qemu-img 的参数,发现有一个 -t 的参数可以指定 cache mode,有如下 5 种选择:
writeback/unsafe:app —-qemu write—-> host page cache — os flush —> disk cache — hw flush —> disk
none: app — qemu write—-> disk write cache —- hw flush —> disk
writethrough: app — qemu write—-> host page cache, disk
directsync: app — qemu write —> disk
通过阅读 cdi-importer 代码,可以看到它使用的是 writeback,即先将转化好的数据写入缓存中,提高速度。
然后我也发现了 directsync 这个选项,就是不使用缓存,直接将数据写入磁盘,这正是我想要的啊。
重新改了下 cdi 的代码,编译,制作镜像,创建 pod,还真的是再也没有出现 OOM ,到现在问题全部解决了,真的爽啊~
5. 总结一下¶
由于是第一次处理 OOM,因此这个排查的过程,花了不少的时间,不过归根结底还是我对基础的不牢固导致的。
在此之前,我潜意识里以为只有进程实际占用的内存才是 oom 的依据,没有想到缓存分为两种:读缓存和写缓存,读缓存是可随时回收的内存空间,不会引起内存问题,但写缓存,是不能随时回收的内存空间,只有将数据存入磁盘后,内在才能回收,这部分是有可能会引起内存问题的。
基本功不扎实,靠着搜索引擎,往往是事倍功半,平时得多刻意去巩固诸如计算机基础、网络基础的相关知识,才能在关键时刻用上。