3.2 调度利器(二):污点与容忍度(压力驱逐)¶
将一个 Pod 分配到某一个可以满足 Pod 资源请求的节点上,这一过程称之为调度。
理想情况下,你的集群中,有足够的资源能让你创建你期望的 Pod,如此一来,你就有理由不关心你的节点的资源还剩多少,有理由不关心 K8S 调度 Pod 的细节。
可事实上,你的集群资源是有限的,为了能让节点资源得到合理分配、有效利用,需要你对节点进行规划。
比如哪些机器是高性能的机器,哪些是普通机器,哪些是专用机器,尽量避免让普通的应用跑在高性能的机器上。
除此之外,有些应用,出于高可用的考虑,还需要应用部署多个副本,并分散开在不同的域里。
而关于这些内容,可以分成三个部分:
标签与选择器
污点与容忍度
亲和与反亲和
上一篇文章已经介绍了 标签与选择器,本篇文章讲一下 污点与容忍度。
1. 通俗理解污点¶
打个比方,你去医院里看病,在医生的诊断之后,了解了你的病情后,准备给你开点药。
但开药也讲究对症下药,同样是发烧,给大人吃的药和给小孩子吃的药是不一样的。
因此为了防止滥用,药店会给不同的退烧药就设定适用范围(作用等同于 K8S 中的污点):
阿司匹林:适合成年人使用(做为退烧药,禁止儿童使用)
布洛芬:适合儿童使用
医生根据患者的病症,诊断出是发烧了,于是就在系统中寻找退烧药(等同于 K8S 的调度过程),找出来有两种退烧药 阿司匹林 和 布洛芬。
而根据患者是儿童,那么因此会把阿司匹林给排除掉,最后选择布洛芬。
这就是污点的作用,在本例中:
阿司匹林 和 布洛芬,即为 K8S 中的 Node
药品上的适用范围,就是打在药品(K8S 中 Node) 上的污点
而找药的需求,就是 K8S 中的 Pod
可以看出,污点是从 Node 的角度,禁止那些不能容忍这些污点的 Pod 调度过来。
2. 污点与标签区别¶
污点与标签有什么不同呢?这是我们在学习污点时首先要搞清楚的问题。
由于标签和污点工作原理的不同,他们的适用场景也不一样。
标签通常用于为 Pod 指定分组,规定了 Pod 只能调度到这些分组里的 node 中,这是一种强制的做法。
污点通常用于将 Node 设置为专用节点,默认情况下普通 Pod 是无法调度过来,仅当你在 Pod 中指定了对应的容忍度才能调度。
3. 容忍度与污点¶
污点 也是打在 Node 上,可以理解为对外公开自己的“缺点”(并非真的缺点),想调度到我这边的,请明示说出你可以容忍我的缺点的,不然是调度不过来的。
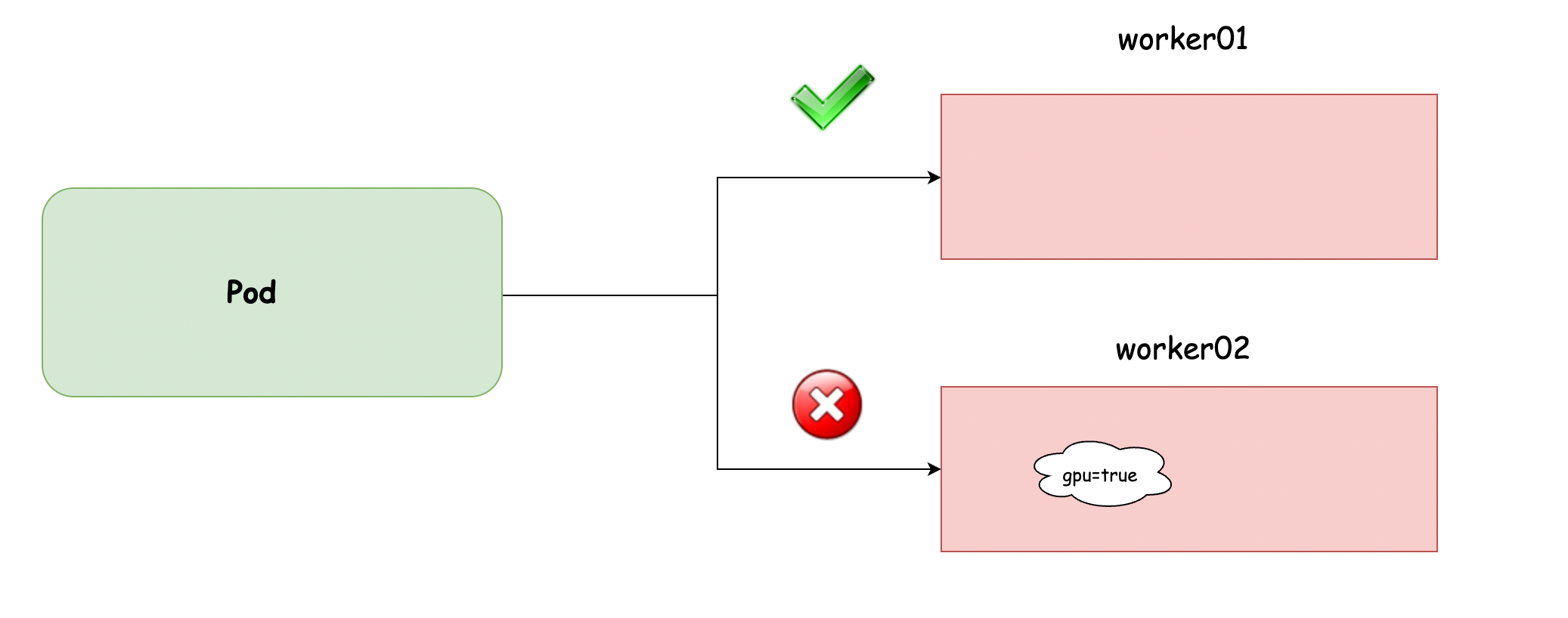
使用如下命令为 worker01 打上污点,而 worker02 却没有任何污点
kubectl taint nodes worker02 gpu=true:NoSchedule
正常你创建的 Pod,没有进行特殊的配置,是无法调度到 worker02 的,只能调度到 worker01,即使你使用了 nodeSelector
只有你在 Pod 上加上了如下的容忍度(在 .spec
下),才能有可能地创建到 worker01 上
tolerations:
- key: "gpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"
千万要注意的是,上面说的是有可能,而不是一定。
如果要标准地调度到 gpu 的机器上,还要配合前面的 2. 如何打标签?[^1]
标签:实现精度地调度的需求
污点:避免产生不必要地浪费
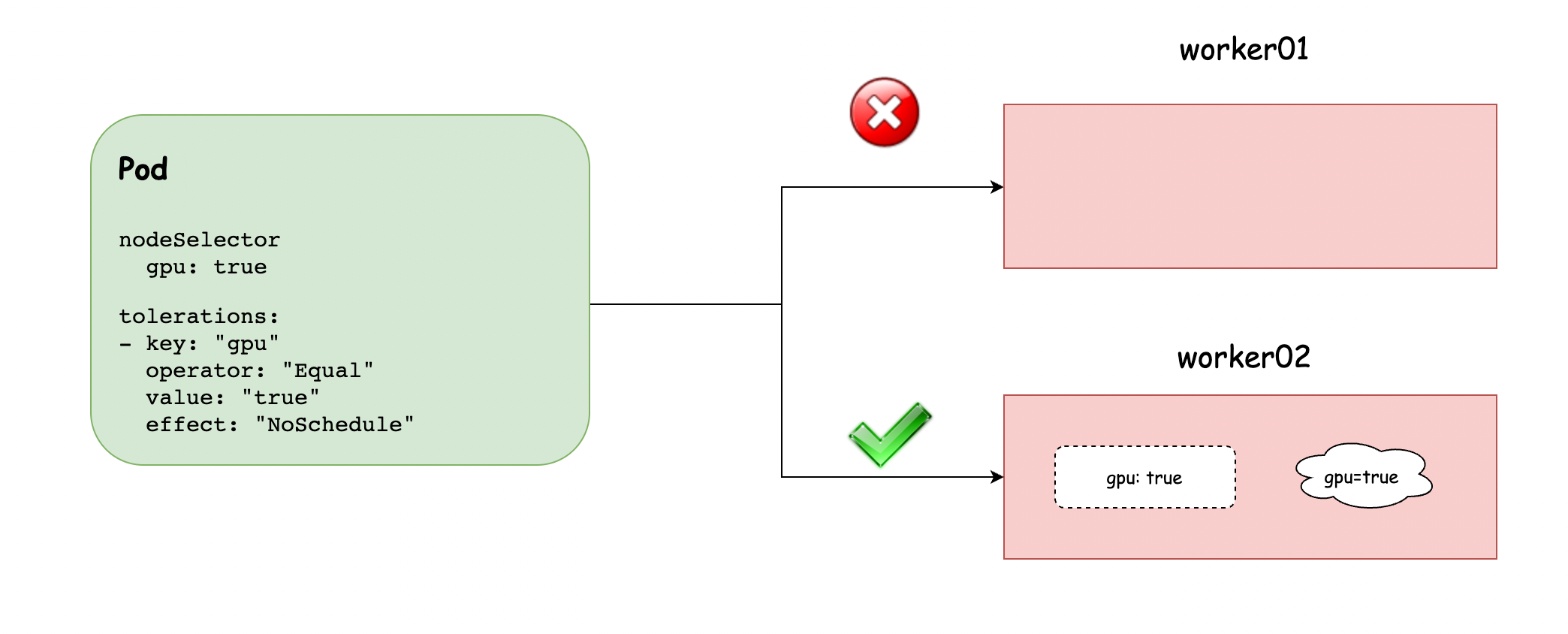
上面节点上的污点的,我再翻译一下,意思是该机器上有 GPU,没有指定需要 GPU 的容忍度 的 Pod ,不能调度过来。
如果不使用 GPU 的 Pod 也创建到有 GPU 的节点上,那就是浪费资源,这是不能理解也不能允许的。
而后面的容忍度,意思是,我可以调度到有 gpu 的机器上,如果没有指定这个配置,就无法调度到 GPU 的机器上。
如果要删除原有的污点,可以在上面添加污点的命令最后加个减号 -
kubectl taint nodes worker02 gpu=true:NoSchedule-
4. 容忍度的配置¶
容忍度,由几个关键字段组成:
key:键(必填)
value:值,当 operator 为 Equal ,value 必填,当 operator 为 Exists ,value 就不用填写
operator:操作,可以为 Exists (存在即可匹配) 或者 Equal (value 必须与相等才算匹配)
effect:影响,有三个选项:NoSchedule、PreferNoSchedule、NoExecute
其中 effect 比较难理解,这边挑出来专门说一下,要理解 effect,就要理解 容忍度与污点的过滤原理。
简单来说,一个 Node 上可以设置多个污点,一个 Pod 也可以设置多个容忍度。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点,特别是以下情况:
如果未被过滤的污点中存在至少一个 effect 值为
NoSchedule的污点, 则 Kubernetes 不会将 Pod 分配到该节点。如果未被过滤的污点中不存在 effect 值为
NoSchedule的污点, 但是存在 effect 值为PreferNoSchedule的污点, 则 Kubernetes 会 尝试 不将 Pod 分配到该节点。如果未被过滤的污点中存在至少一个 effect 值为
NoExecute的污点, 则 Kubernetes 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 或者将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
5. 污点的原生用途¶
在原生的 kubernetes 中是如何使用污点的呢?
在 kubernetes 的每个集群节点上,都有一个 kubelet 服务,它会监控集群节点的 CPU、内存、磁盘空间和文件系统的 inode 等资源。
当这些资源中的一个或者多个达到特定的消耗水平, kubelet 会主动给节点打上一个或者多个污点标记,这些标记的 effect 为 NoExecute
比如内存比较紧张的话,会打上 node.kubernetes.io/memory-pressure
比如磁盘比较紧张的话,会打上 node.kubernetes.io/disk-pressure
比如 pid 比较紧张的话,会打上 node.kubernetes.io/pid-pressure
而如果该节点上,已有一些 Pod 在运行,并且这些 Pod 没有配置以上三种对应的容忍度,则 kubelet 会开始驱逐的流程,一个一个的驱逐,直到节点不再有存在资源压力为止,才会清除污点,结束驱逐。
通常还会带上一个 tolerationSeconds,它意思是在污点出现后,Pod
还可以正常工作多少时间,也就是延迟多久再进行驱逐。
除了以上污点之外,还有其他常见的
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状态Ready的值为 “False”node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状态 Ready 的值为 “Unknown”。node.kubernetes.io/network-unavailable:节点网络不可用。node.kubernetes.io/unschedulable: 节点不可调度。
而这些污点的 effect 通常为 NoSchedule,以防新的 Pod 调度过来,却无法正常工作。
6. 污点的进阶开发¶
污点的原理上面已经剖析得差不多了,在实际工作中,它被广泛应用于实现节点的专有专用。
但要实现节点的专有专用,还要有标签与选择器(nodeSelector)的配合才可以。
因此,你想要将 Pod 调度到专用节点上,你要添加 容忍度的配置,还要添加 nodeSelector 的配置。
那有没有办法,将这两个步骤,再简化成一个步骤呢?
K8S 中有一个 准入控制器 的概念,它可以理解为一个定义在 api-server 组件中的插件,当你在对对象进行操作时,这些插件可以拦截 api 的请求,并进行一些操作,
根据操作的不同,这类准入插件可以分为两类:
MutatingAdmissionWebhook:可以变更对象的配置
ValidatingAdmissionWebhook:可以验证对象
准入控制过程分为两个阶段。第一阶段,运行变更准入控制器。第二阶段,运行验证准入控制器,有某些控制器既是变更准入控制器又是验证准入控制器。
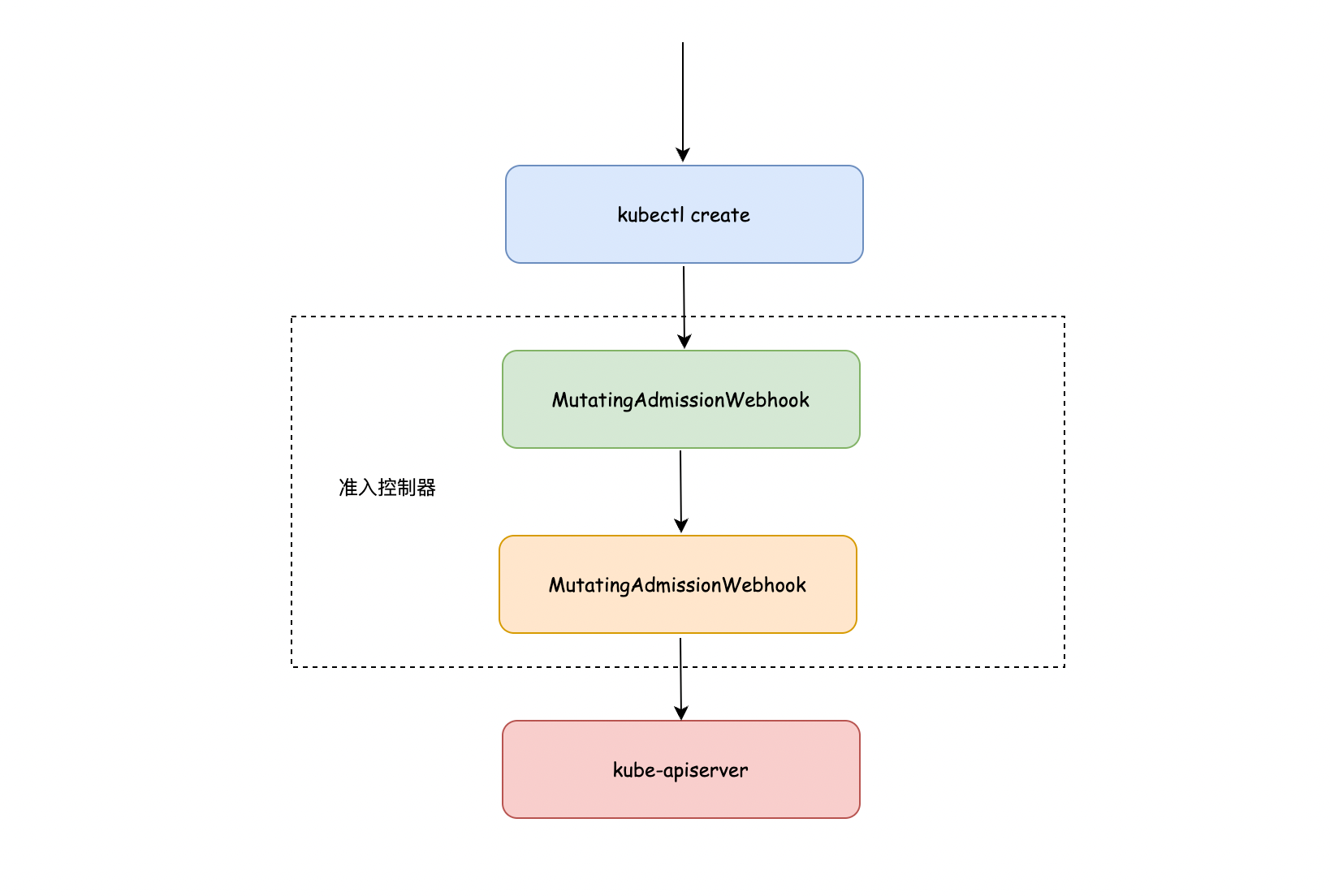
如果任何一个阶段的任何控制器拒绝了该请求,则整个请求将立即被拒绝,并向终端用户返回一个错误。
而 MutatingAdmissionWebhook 可以变量对象的配置,这不正是我们所需求的吗?
我们可以自定义一个MutatingAdmissionWebhook ,当检查到 Pod 有如下的容忍度时
tolerations:
- key: "dedicated"
operator: "Equal"
value: "gpu"
effect: "NoSchedule"
就自动往 Pod 中添加如下的选择器配置,当然如果原有的 Pod 已经有了该段配置,就可以直接覆盖或跳过。
nodeSelect:
gpu: true
自定义的准入控制器,其实也不难,Kubernetes 其实本身自带了非常多地准入控制器,可以模仿一下,写起来并不麻烦,具体的代码在:src/k8s.io/kubernetes/plugin/pkg/admission/
要注意的是,有些准入控制器,即是MutatingAdmissionWebhook 也是 ValidatingAdmissionWebhook。
下边我挑选一个 Kubernetes 自带的准入控制器,带你了解一下 MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook 是怎样工作的。
7. PodNodeSelector¶
创建一个全新的 namespace,名字叫 iswbm
kubectl create namespace iswbm
然后再使用 kubectl edit 命令,在该 namespacce 上添加 annotation 时(或者也可以通过在 apiserver 上指定对应的配置文件)
apiVersion: v1
kind: Namespace
metadata:
annotations:
scheduler.alpha.kubernetes.io/node-selector: env=test
name: iswbm
有了该 annotation 后,在该 namespace 下创建的 Pod 都只能创建到有 env=test 标签的 Node 上 – 这是 MutatingAdmissionWebhook 的部分
若 Pod 自己的 nodeSelector 和 PodNodeSelector 做完交集后,没有一个 node 满足条件,则会直接拒绝 – 这是 ValidatingAdmissionWebhook 的部分
这个实现的方式就是通过 PodNodeSelector 这个准入控制器,自动给该 namespace 下的 Pod 加上 nodeSelector 。